Playkot 2D artist Tatiana Mironova has detailed how the studio implemented image-generating tools into their pipeline to create UI elements for Spring Valley. Here is what the team learned during this process and what are the clear advantages and pitfalls of training your own models.

Tatiana Mironova
It all started with a company-wide question: how can we spend less time on current tasks without compromising quality?
Many of us had previously explored deep learning models and genAI tools out of pure enthusiasm, but understanding if we could integrate AI into our processes required a more systematic approach. Now almost all teams at Playkot are experimenting with neural networks for their tasks. We share experiences in AI-themed chats on Slack, and when someone has a mini-breakthrough, we adopt their solutions.
So let’s talk about what we’ve tried in our UI team while working on Spring Valley.

Midjourney: went looking for gold, found copper instead
I began actively exploring neural networks at the beginning of this year. I spent three to four days just getting to grips with the tools: understanding the technologies and approaches, figuring out the technical side of things.
I first tried Midjourney as it seemed the most accessible option — we already had a corporate account for experiments. Quickly enough, I realized that it wouldn’t help us save time on creating icons: in the fourth version that I was testing, the image quality left much to be desired. In the fresh fifth version, the quality improved significantly, but for our tasks, the results still required substantial revisions.
The biggest stumbling block was that Midjourney couldn’t match our required style. In a nutshell, it has the whole internet uploaded into it, so it produces very unpredictable results, and you can’t train it to match your style.
Nevertheless, it turned out that Midjourney is a decent auxiliary tool for concepts or for generating individual elements. If you need to communicate an idea or to find some form for it, it handles that well.
For instance, I needed to create a cameo ornament. I spent some time on generation and realized that none of the results suited me — it would be easier to build everything in 3D. But the cameo portraits themselves looked decent: they didn’t stand out from the style, didn’t have two noses or crooked mouths, so why not use them?

In 3D programs, there’s a tool called a displacement map: it adds height to the bright areas of an object and indents to the dark areas. I quickly cut out the cameo from Midjourney in Photoshop, applied my own material to it, and didn’t have to draw the portrait by hand. I spent the same amount of time on the icon as I initially planned, but the cameo image ended up being interesting, more natural.
And here’s another example: I needed to make a branch with crystals. It takes quite a while to think through how each of them will look. I gave Midjourney an example, and it generated a plethora of these crystals. After that, I chose the generation that suited me the most, added the required seed (i.e., the variable of that generation) to the prompt, and quickly obtained enough graphic material, which I ultimately used in the icon.
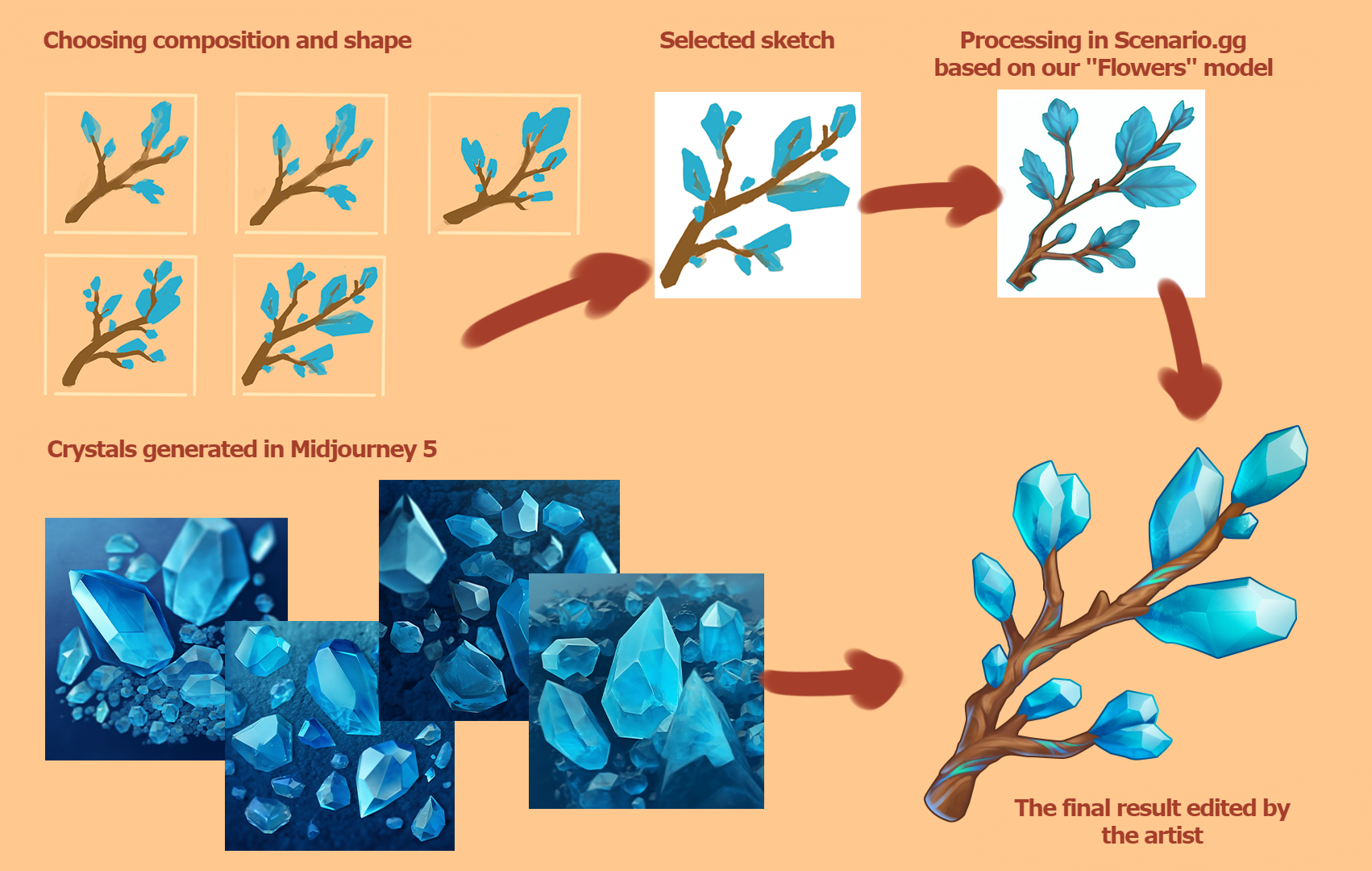
Stable Diffusion: a hypothesis that proved true
Then I started experimenting with Stable Diffusion. It allows you to take an already created model as a basis, add your images, and train it on this dataset. By that time, our project had accumulated many good icons in the needed style, which could be used for datasets.
Stable Diffusion has several training methods: Dreambooth extension, Hypernetwork, LoRA. The idea was to test each of them and see what would work. We dismissed LoRA right away because it’s better suited for faces and portraits. However, Dreambooth extension worked well.
Training a model is a risky venture. At first, you might get the deceptive feeling that you will train it successfully once and then reap the benefits. But when you start realizing how many details need to be taken into account… If you see that the results are not great, you need to start over. Almost all AI models are very demanding on video cards, and if your computer has limited video memory, retraining will take another three hours. As a result, any minor error extends the process, and there’s no guarantee that the result will be good enough to use.
Once I set the model for training and went to sleep. My plan was to set an alarm, get up, and check the results. I woke up at 3am, and it generated a pretty decent bouquet of tulips. I was like, “Oh, finally some kind of result!”
These three images of tulips proved that the game was worth the effort:

When I realized that Stable Diffusion had potential, the issue with the technical side of the process needed to be addressed. Computer power is the main blocker, and not everyone on our team has equal opportunities in this regard. From the experiences of colleagues from other companies, we learned that a workable method was to allocate a separate computer as a server through which all generations would run.
At the same time, we tried various life hacks from other AI enthusiasts: reviewed a vast number of tutorials, looked for other suitable models, but eventually found another solution — Scenario.gg, a Stable Diffusion-based service specializing in game assets.
Servers with higher technical capabilities solved our problem with power, and there also was a nice bonus: while Stable Diffusion may make a beginner user, who hasn’t delved into machine learning before, bug their eyes out, Scenario.gg’s interface is intuitively understandable and already tailored to our requests. You can choose whether you want to train the model for concept art, illustration, or asset generation.
On external servers, the process went faster, and we finally started getting more consistent results. The image-to-image method worked best, where you upload the original picture and get the result in the style that the model was trained on. I will tell you about specific tasks where this method helped us.
Strangely enough, the most challenging icons to produce are all sorts of organics: plants, fruits and vegetables, food, flowers. You may think, well, they’re just flowers, are they so difficult to draw? But constructing organic shapes takes a lot of time. And that’s where the AI model excelled.
For one of my tasks, I needed to draw a wedding bouquet. Prior to that, I had already collected a dataset from our flower icons:

Using the img2img method, I fed a reference bouquet to the model for it to analyze, process, and merge with our style.

I set the maximum number of generations to 16 at a time. While I was working on another task, it generated a huge number of options for me. Some of them turned out to be pretty good: satisfying in terms of form and mass, color, and rendering. These are the best results that I selected:

As you can see, the ribbons on the bouquets turn out to be quite unique, but this is exactly what can be quickly corrected by hand. As a result, after the revisions, this is what the bouquet looked like when we added it to the game:
![]()
The goal was achieved, and I saved almost 50% of the time on this task. Manually, I would have been drawing such a bouquet for eight to 10 hours, but using deep learning models, you can generate icons in 30-40 minutes, select the best ones, make minimal corrections, and complete the task in four hours (not counting another hour for compiling a dataset).
Or here’s a flower crown, a very urgent task that I completed in four hours — generating different options while dealing with another task.

Disclaimer: this won’t work that well for all objects. Firstly, a huge advantage is that we have gathered a good dataset from our own icons with flowers — diverse, with good rendering and forms, and in a unified style. And secondly, the basic model of Stable Diffusion, most likely, already contains a huge number of flowers. Roughly speaking, we combined all the best in this bouquet.
Food is another great category for Stable Diffusion. Let’s say we need to create a burger icon: first I set the parameters with a prompt, and the results were as strange as possible — look at the plates with corn in the screenshot.

But the img2img method worked well: I found a suitable photo, quickly processed it, and Stable Diffusion combined the reference with the needed style:

I selected the most successful results of the generation. Of course, it’s clear that the patties here are very strange, and there are too many sesame seeds. And the request from the game designers was for a vegetarian burger: in Spring Valley, we have such a concept that we don’t kill animals, don’t really catch fish, and don’t eat meat.

I corrected all this and made the icon less “noisy” manually, but still saved about an hour and a half to two hours of time. This was the final version that went into the game:
![]()
Another successful example is an orange cake. Here’s the dataset I created based on our pastry icons:

These are the results I received from the model:

And here’s how the cake looks after a few corrections — it has already been incorporated into the game:
![]()
The combination of “Stable Diffusion + a handy service with powerhouse servers + the img2img method” can be a game changer for UI teams, as long as they do some homework: carefully curate datasets and invest some time in training.
Let’s say, for instance, I was assigned to create an icon with a bunch of bananas. We already have a decent dataset — there are many fruit icons in our game. Given the correct reference, the model provides an excellent preliminary sketch: good color accuracy, texture, unevenness, even the top of the banana is green. Sure, there are adjustments to be made, but they won’t take up too much time.
The only hitch here is copyright. If a recognizable stock composition is used as a reference, it’s necessary to meticulously verify if the license allows you to use this image, and to seek out alternatives with a Creative Commons license.

These cherries above, for example, fit well into our aesthetic, and the necessary edits here would be minimal. But it’s easy to see that they’re made from a stock photo — almost a direct match. What should an artist do in this case? Collage, modify, consider what elements can be removed, transform this to achieve a different result. This also takes additional time.
The legal side of the issue is, in principle, a large and underexplored area. For instance, all works generated by neural networks, especially in the completely open-for-viewer platform Midjourney, are not subject to copyright. In legal terms, I can now go to Midjourney, print any generation on T-shirts for sale or put it into a game. And if someone recognizes where this was generated, finds it through keywords, and uses the same illustration in their game, who would be right? It’s hard to predict how events in this area will develop, and this represents yet another potential risk.
What doesn’t work so well
The further we stray from organic forms, the worse the results tend to be. Stable Diffusion struggles to correctly construct straight shapes and lines, so I have yet to achieve decent results for all items requiring precise formation.
Each of us has seen a bottle thousands of times, and the human eye immediately detects any distortion. Particularly in an icon, where a single object is confined to a square — if the bottle looks crooked, everyone will notice it.
In the screenshot below, I’ve marked with purple checkmarks the elements that I could potentially use in my work. However, that’s only three images out of the entire bulk of generations. The odds increase that you’ll waste your time and end up with nothing, as you’ll still need to fix the result with shapes in Photoshop. It would be easier to draw this bottle with those same shapes or model it in 3D according to a familiar pipeline.
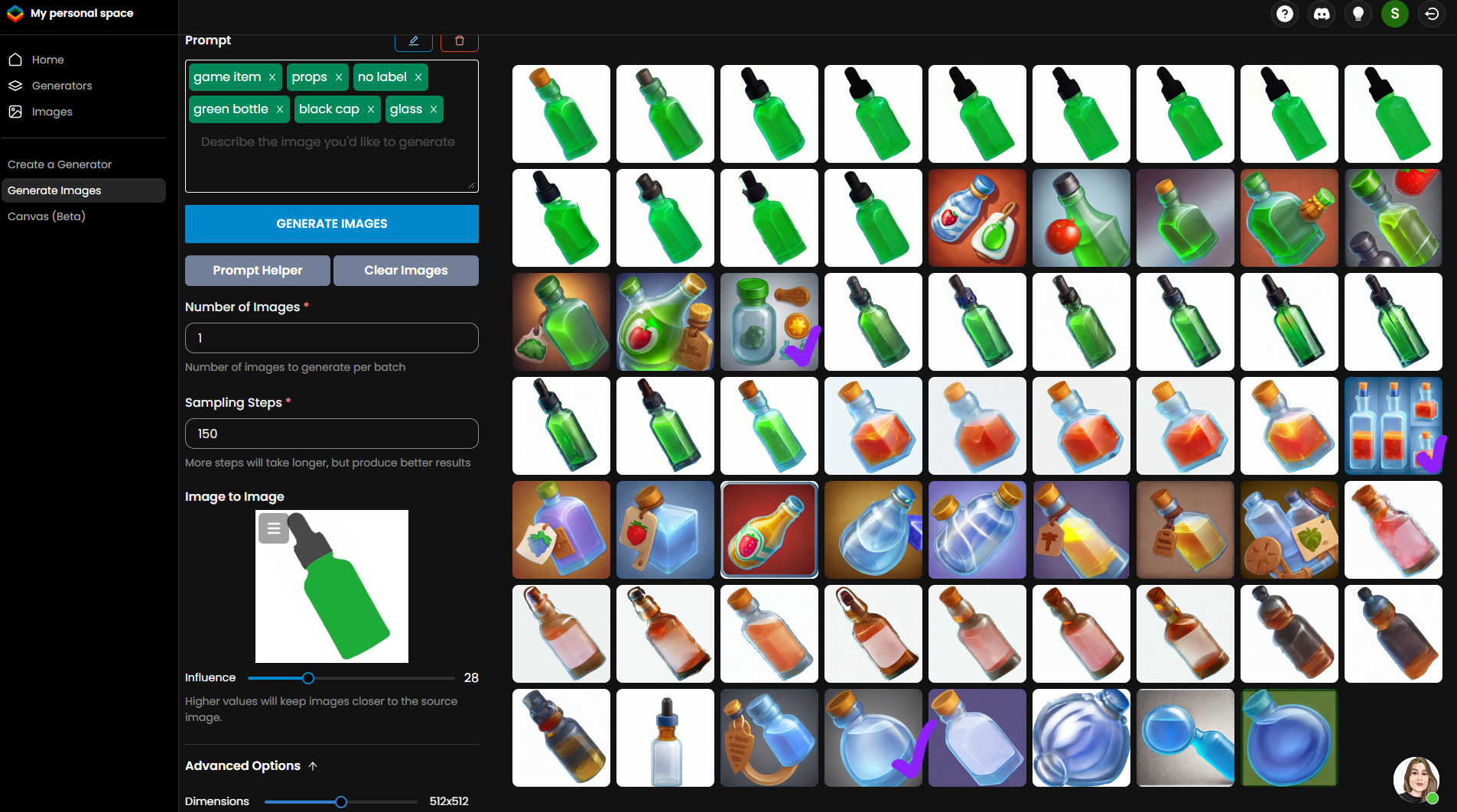
Deep learning models excel in repetition. They repeatedly use the elements you fed them with, and if they encounter a bottle of a particular shape once, they’ll continue to generate that shape and won’t produce anything fundamentally new.
Another challenge is explaining to the model exactly what it sees and how it works. There are different training methods, but the most practical one involves analyzing the uploaded images and creating a text description for each. The person training the model can delve into this text file and check the description.
Sometimes, the AI makes mistakes or doesn’t understand what it’s seeing. For instance, a text might read: “A green bottle with a wooden cork and liquid inside,” when the bottle is actually transparent. If you let this slide, every time you ask it for a green bottle, it’ll keep serving up transparent ones, no matter what. You could manually check each description, but what if you have hundreds of such images? The cost of fine-tuning is steep.
I’ll show another example of an unsuccessful generation on a large dataset: here you can notice that sometimes the result matches the aesthetic, but you can’t figure out what’s depicted. Even though I can recognize where the AI got individual elements from.

Building icon datasets: mastering the art of living easy
Here are the lessons we learned in the process of experimenting with generative models:
- Don’t feed it images with semi-transparency, otherwise it will fill these areas with horrendous artifacts, and there still won’t be any semi-transparent backgrounds in the generations;
- Train the model on objects with a neutral white background — there’s a better chance you won’t have to painstakingly cut out objects in Photoshop and wonder if it would’ve been quicker to just sketch everything manually with vector shapes;
- Find a balance between a dataset that’s too small and one that’s too large. From my experience, everything that was trained on minimal sets of 7-8 images didn’t turn out well. The results also notably degrade with large diverse datasets;
- When generating icons, it’s better to divide datasets by entities. That is, separate datasets for bottles, another for fruits, and another for keys;
- When training the neural network, if possible, check the text descriptions to ensure it correctly identifies what’s depicted in your dataset.
To sum it up, we’re still quite a way off from the point where generative models can do our job for us, but we can use it as another tool. In addition to organic icons, which we’re already pretty good at, we can generate auxiliary materials, patterns, posters, backgrounds, and parts of backgrounds — all these rocks, trees, and flowers usually take up a lot of time, it’s meticulous work. Generating them in the required style and collaging them is much faster.
We haven’t yet scaled these approaches across the entire team, so they’re not 100% incorporated into our processes. We feel it’s too early to tackle this until we’ve explored all possibilities. But I believe that AI models will allow artists to create, in some sense, more complex things.
When I plan a task, I estimate what I can accomplish within the given timeframe. It’s like the meme with two cowboys, where one is the manager and the other is the designer. “How much time will you spend on this task?” vs. “How much time do I need to spend on this task?” For the same amount of time, we’ll be able to create more complex things. And that’s a huge advantage.