In details about the work on A/B tests, they tellIlya Tumenko, Publishing Director at AppQuantum, and Oleg Semenov, Marketing Lead at Appbooster.

Ilya Tumenko and Oleg Semenov
The material was prepared by AppQuantum on the basis of the webinar of the same name.
A/B tests: what is it and why are we needed
A/B tests (also known as split tests) are a method of comparing two states of one element. They help to increase the conversion and profitability of the project. The key metric in their assessment is revenue. The tested element can be anything: subscription screen, onboarding, advertising creative, etc.
History of appearance
A/B tests became popular in the era of websites, when their owners were chasing higher conversions. They started changing page elements to make them more attractive to visitors. But then it was much easier to conduct the test.
It looked like this: the Google Optimize tag was inserted, and the tested elements were configured in the visual editor. Then the experiment was started. Users were randomly divided into two parts. One of them received the old version of the element, the second — the modified one.
Over time, A/B tests became more complicated and improved. With the development of the mobile market, they began to be actively used for application elements. But most developers avoid A/B tests, because it is considered that it is long, expensive and time-consuming to conduct them.
Let’s analyze the most common objections of developers who refuse A/B tests without even trying.
Working with objections
- The developer knows how to improve the application without a test
This is the misconception we encounter most often. The developer thinks that he already has enough experience in the development and design of applications. He believes that he can calmly fix all the weaknesses himself, after which the indicators will instantly increase. But, even based on experience, it is not always possible to draw the right conclusions and make the right decisions. Even from regularities there are exceptions — there are no universal options.
- You can simply compare “before” and “after”
The developer is convinced that you can simply make changes one by one, comparing the results. At the same time, it is often not taken into account: the effect of changes does not come immediately, it takes time. For example, it may take a week. But a lot can change this week. Metrics are affected not only by the changes you have made, but also by new competitors, the fill strategy, etc.
So that no factor affects the accuracy of the result, two elements need to be compared simultaneously.
- A/B tests are long and expensive
This is a logical remark. Deep product components are often tested in mobile games. One test is not enough here: to find the optimum, you need patience and money.
Nevertheless, it’s worth it.
We worked with one application whose monetization was based on subscriptions, among other things. For about six months, it worked at a loss (it was at its peak – $ 300 thousand). The problem was in onboarding and paywall. We have conducted more than 50 of their tests, found suitable options for us in terms of indicators. After that, the application came out in a plus, recouped the investment, and today brings a stable income of hundreds of thousands of dollars. This would not be possible without A/B tests.
Therefore, the only honest answer to the objection that testing is long and expensive: yes, it is. Testing costs will have to be budgeted from the very beginning.
Developing the right hypothesis
The preparatory stage for effective A/B testing is the development of the correct hypothesis. Each hypothesis is created in order to influence a certain metric.
Suppose we want to increase profits and work for this with the retention rate metric. We build hypotheses, test them a lot, formulate hypotheses again, and the metric remains at the same level. In this case, it is customary to call the metric inelastic.
Formulate expectations within the team: what should the hypothesis affect? What will it change? Study user behavior, product features, and determine the desired gain. All this will help to formulate a hypothesis that will really affect the metrics. This will save time, effort and money on tests. In the next section, we will tell you how else you can conduct effective tests with minimal costs.
The Secret of Cheap A/B tests
1. Statistical significance
A/B tests can be made cheaper if you know a simple loophole — use statistical significance tools.
For example, we are testing paywalls. For this purpose, we take only a cohort of users who have reached the paywall — the rest are irrelevant to us. As a result, we get 2000 users who are divided in half (according to the number of tested elements, we have 2 of them). There were 140 conversions in Group A and 160 in group B.
The difference between the options is small. Because of this, it is unclear how effective changes we have made. This is where statistical significance comes to the rescue: it determines exactly how many users were affected by the change. Special calculators, links to which you will find below, will help to make calculations.
Calculators digitize the running test and make it clear how it proceeds. When calculating, they use one of two approaches: classical frequency and Bayesian. The first approach highlights one of the best tested options. The second one allows you to specify how much one of the options is better than the others as a percentage.
Let’s try to interpret the result of our test through one of the most common Mindbox calculators. It relies on the classical frequency approach.
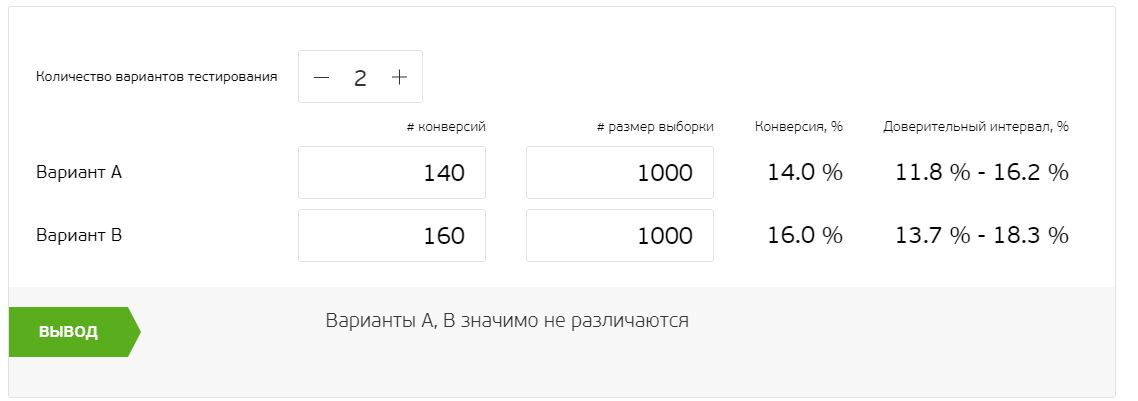
In the example for 1000 users, the results do not differ much — it is impossible to draw a clear conclusion. Let’s run the same introductory data through the AB Testguide calculator using the Bayesian approach.
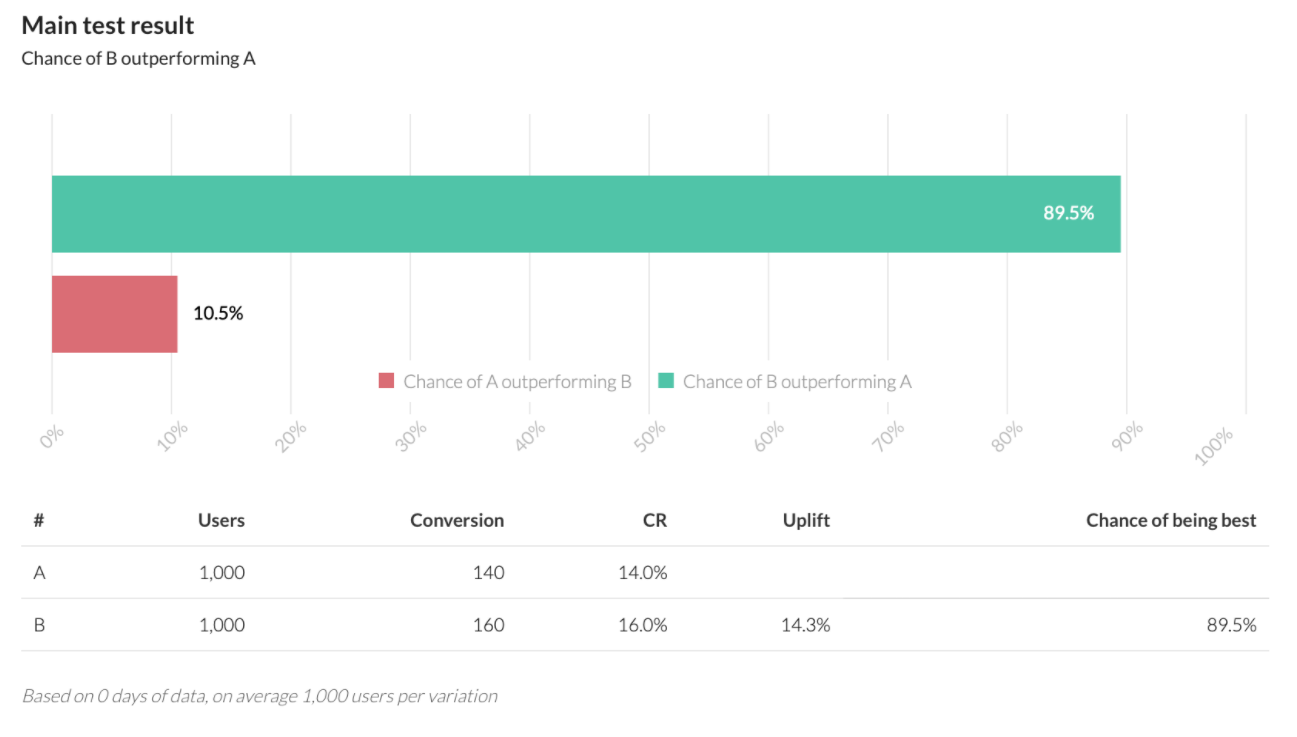
We see that he gives an unambiguous answer: option B is 90% more successful than the others. With the Bayesian approach, we save time and reduce the number of test iterations — respectively, the money spent. It is important to understand that we do not run the result through 100 calculators until we get a satisfactory result. The result is the same in both cases, but the interpretation of the data is different.
2. Radical tests
Radical tests, where the tested options are as far from the control as possible, will also help to achieve maximum test efficiency with minimal investment.
When the process of working with tests is just being built in the product team, the closest options to the current one begin to be tested. If we test the offer prices, and the initial value is $4, then $3 and $5 start testing more often. You shouldn’t do that.
We are convinced that it is necessary to conduct tests radically. The reference price of the offer is $4? Then put the values as far from it as possible — $1 and $10.
Advantages of radical A/B tests
- They are indicative. A radical test gives a strongly positive or strongly negative effect, so it is easier for us to evaluate the result of changes. Even if the test was unsuccessful, we understand which way to move. An indecisive test inspires the illusion of an optimum found. The $5 option lost compared to the $4 option — there is a feeling that once you lost a very close to the control option, it is impractical to test the remaining large values, they will definitely not win. From our experience, this is not the case.
- You can save money. There are more iterations in the radical test, but they are cheaper and achieve the desired significance on a smaller number of conversions. We need less data for a confident conclusion.
- The margin of error is lower. The closer the tested options are, the higher the probability of randomness.
- A chance for a pleasant surprise. Once we tested a very high price for an offer in AppQuantum — $25. Our entire team and development partners were sure that it was too expensive, and no one would buy at such a price. The competitors’ offer, similar in content, cost a maximum of $15. But our version eventually won. Pleasant surprises happen!
3. Degrading tests
A quick and cheap way to test a hypothesis is to do a worsening test. Its essence is that instead of improving the element, we greatly worsen it or simply exclude it. In the vast majority of cases, it is easier and faster, because the developer has to spend money, time and effort to develop a good solution, and it is not yet a fact that the improvement will raise the metrics.
Example of a worsening test
From user reviews, the developer realized that there was an incorrect tutorial in the application. He is convinced that he will fix all the mistakes now, and the metrics will increase. If the improvement should raise the metrics, it turns out that the deterioration should “drop” them? If so, you can worsen the tutorial and see how the metrics are really amenable to change. After the developer has made sure that the changes make sense, you can start improving the element, investing effort, time and money in it.
However, this does not mean that such a degrading element should be done poorly. Sometimes the average or poor quality of the implementation of the tested element is worse than any implementation in principle. In this case, even a worsening test can give a positive result.
On what it is worth conducting worsening tests:
- narrative and localization quality (exception: narrative-driven genres and verticals);
- user interface (exception: offers and paywalls;)
- User Experience (in this case, the degrading test affects the activity and reviews of the application);
- tutorial and onboarding (changes in them have an effect, but often not as significant as expected).
4. Many changes per test
Most often it is inefficient to test several changes at once. It makes no sense to test 10 elements if the result of 8 of them is obvious. But there are exceptions to each rule: sometimes you can test many options at once for the sake of saving on the test.
You can make many changes at a time when:
- we know that changes work effectively only in the aggregate;
- we are sure that none of them will work in the negative;
- it is easier to test several inexpensive elements at once at a time.
***
We figured out how to conduct cheap tests. Now let’s try to figure out how to calculate their result as accurately as possible in order to reduce the time and effort to conduct them.
Unit Economics in A/B testing
When searching for the most promising places in the funnel of your product, we recommend using the methods of unit economics. It helps to determine the profitability of a business model by revenue from a single product or customer. In mobile apps, revenue consists of app or subscription sales or advertising revenue.
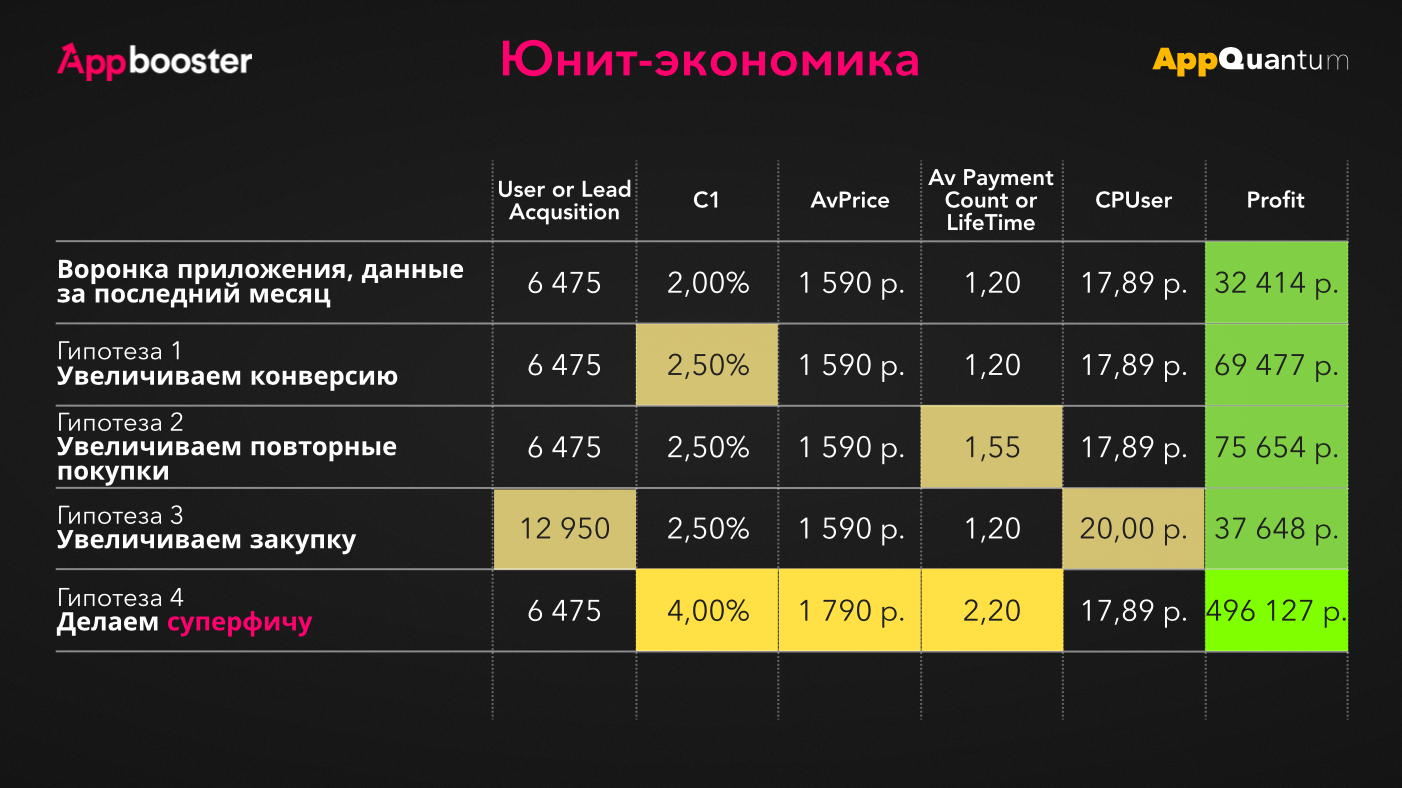
The diagram shows an example of a real application: 4 hypotheses and the calculation of profit from them using unit economics. We eliminated the intermediate metrics, leaving the main ones: the number of users in the purchase, the conversion of the client, the average price, the number of purchases per paying user, the cost of the user and the profit from the stream.
Hypothesis 1
We want to increase the conversion rate in customers. We will achieve an increase of 0.5% — this will bring 69,477 rubles.
Hypothesis 2
We want to increase repeat purchases. 20 customers make 24 purchases, and we need to get 20 customers to make 31 purchases. Concentration on specific metrics and a clear formulation of the problem help to outline the range of possible hypotheses. What are we going to do? Perhaps we will conduct a push campaign or give the player fewer lives.
The result is a profit of 75,654 rubles.
Hypothesis 3
We will increase the purchase: we will purchase twice as many users. The result is 37,648 rubles . It turns out that this will bring us significantly less money compared to the first and current profit.
Hypothesis 4
At some stage of studying unit economics, the team is visited by the idea of doing something completely unimaginable with their product. For example, create a superfiche that will increase several metrics at once and bring 496,127 rubles. At first glance, the only problem is that its development will take 3 months. However, there are others that we will consider further.
MVP of big features
MVP (minimum viable product) is a test version of the application with a minimum of functions. MVP is created to test hypotheses and verify the viability of the product.
A big feature is not the most effective solution for raising metrics. The product may become too complex, its main value will be eroded. Time, effort and money will be spent on the feature. And later it will also turn out that the problem of the application was not at all that it does not have this feature.
Let’s say we have a huge desire to make a big feature. But we need a guarantee that it should be implemented at all. How to get it? We’ll figure it out.
Algorithm of actions:
- we isolate the biggest bonus and risk features;
- we answer the questions why it will work and why it may fail;
- we are calculating whether the bonus of possible risks is worth it at all;
- we determine the minimum implementation to get a bonus;
- formalize the bonus and risk assessment in the test;
- as a result, we compare the option not only with the control group, but also with alternative ones.

MVP of Big Features: The Doorman Story Case
Let’s take the example of the Doorman Story application, which publishes AppQuantum. This is a time manager in which the player develops his own hotel. A hotel employee must serve visitors for a limited time. Each game mechanic has a timer and a sequence of actions.
We thought: what if we sell the mechanics that open up to the user in other games for free? This is a profitable monetization point: you do not need to produce new content, but you can already sell existing content. To test this hypothesis, it was necessary to change the balance of levels, redo the possibilities of obtaining mechanics, and think over the interface for opening them.
Together with partners from Red Machine (Doorman Story developer studio), we came up with the most lightweight version of the superficies. We have created a unique game mechanics of a paid slot machine with gum, which does not affect the entire game balance and is found only in one set of levels. One mechanics, one art — the economy of the application is not violated.
This example fits into the MVP method of big features: we highlight the main bonus and the main risk. Bonus — we get the opportunity to sell what we already have without spending extra. A risk player may be scared off by the fact that he no longer has all the tools in the public domain, some need to be bought additionally. Because of this, the user may even leave the product.
We have decided what maximum and minimum we expect from this feature and how much the implementation will reflect the idea. We answer ourselves the questions: will it be indicative of what we will do? Can we predict the effect? Can we draw a conclusion from the experiment?
At the same time, you can change the rigidity of the paywall at any time and see if people will continue to play. We won’t be able to say exactly how many times this feature will be bought if it was bought only once. But we can predict the paywalls.
To make sure that this mechanic would really be sold, we had to put the user in conditions where he could not help but buy. That is why we conducted the test immediately with paywall. This helped us to understand how a gum machine is a valuable purchase for a player. This way the risk is measured even better. If people leave when they see an opportunity to buy at a low price, but do not do it, then most likely they do not like the gameplay. If they fall off already on the paywall, they are not satisfied with the price.
We have decided which metrics we are analyzing and what we expect approximately. We have formulated three hypotheses for the feature that we are going to implement. They came up with the MVP of these features, which are made in a maximum of two weeks. We tested these features and got an unexpected result: a feature won the test, which was not betted by anyone from our team and a team of partners. The most simplified mechanics became the winner. In fact, no one considered the best option as the best.
If we had relied on intuition and did not conduct the test, we would have received a less advantageous result. A/B testing allowed us to find the optimum in the shortest possible time.
Risk assessment of the test
When launching the test, we need to assess the possible risks: to understand what can “break down” in each group.
Let’s say that the number of in-app purchases decreases as the conversion rate to the user increases. This is a situation when many users have gone onboarding, but at the same time they leave the application after a short time without paying. This shows a low level of engagement in the app. And although there could have been more users in fact, we began to earn less from them.
Or, on the contrary, we test the number of ad views. From the fact that the ads are on every screen, the user deletes the application on the second session and does not return anymore. Therefore, it is important to find a counter-metric, the changes of which we will also monitor as part of the test.
If the hypothesis is that something may spoil the user’s impression, it is best to monitor the conversion by progress and engagement. It directly affects what we are afraid of. This works, for example, with the same paywall.
Clearing test results
We proceed to the interpretation of the test results. To calculate them objectively, we must first segment the audience.
Segmentation options:
- by demography (more often country, sometimes gender + age. Even the channels of traffic attraction change from this factor);
- by payers (if there is enough data, we make several segments);
- for new and old users (if possible, it is worth testing only new users);
- by platform and source.
It is important to filter out those who are not affected by the changes. If we test some element for users who have reached the 7th level, then, of course, we also take into account those who have not reached this level, otherwise we will get incorrect metrics. We also cut off all those who have not passed the funnel, and any anomalies.
Problems of tests in mobile applications
Mobile tests are more difficult, more expensive and take longer than on the web. The problems begin at the stage of checking the build in the app store. To add a change, you need to reload the build — so a lot of time is spent on moderation. In addition to time, there are monetary costs: for the purchase of traffic, design, control and processing of the test.
Having the latest version of the app is another obstacle. Not all of your users may have an up—to-date version of it – not all of them will fall under the test.
Even in A/B testing, there is a problem of “peeking” (peeking problem) – the point is that the product team draws conclusions and finishes the test ahead of schedule.
Let’s say the app developer has a favorite version, which, as it seems to him personally, should win. To confirm his assumption, he decides to calculate the hypothetically best option using statistical significance. According to calculations, he sees that his favorite version really has a high chance of winning. Based only on this information, he stops the test ahead of time to reduce the time and cost of the test. Although technically the test has not been completed yet, because not all users managed to pass through the tested element.
Often this decision is made too suddenly. Yes, we can predict the approximate test result, but it doesn’t always really work. The conclusion could have been different if the developer had run the entire audience allocated for the version through the test. Therefore, it is possible to “peek” into the test results, but you always need to wait until the entire sample of users passes through it.
It is also necessary to take into account the demographic moment: different options win in different countries. Therefore, it is not a fact that the best option in the USA will win in Russia.
In addition to the above, one of the key problems of the tests: changing reality. That is why the option that was winning yesterday will not necessarily be winning today.
Bayesian Bandit
Let’s move on to the most convenient, modern and fast A/B tests: the so-called “Bayesian multi-armed bandit”. It is tests updated in real time based on the effectiveness of variation. The most effective group is given the largest share. Simply put, this is auto-optimization.
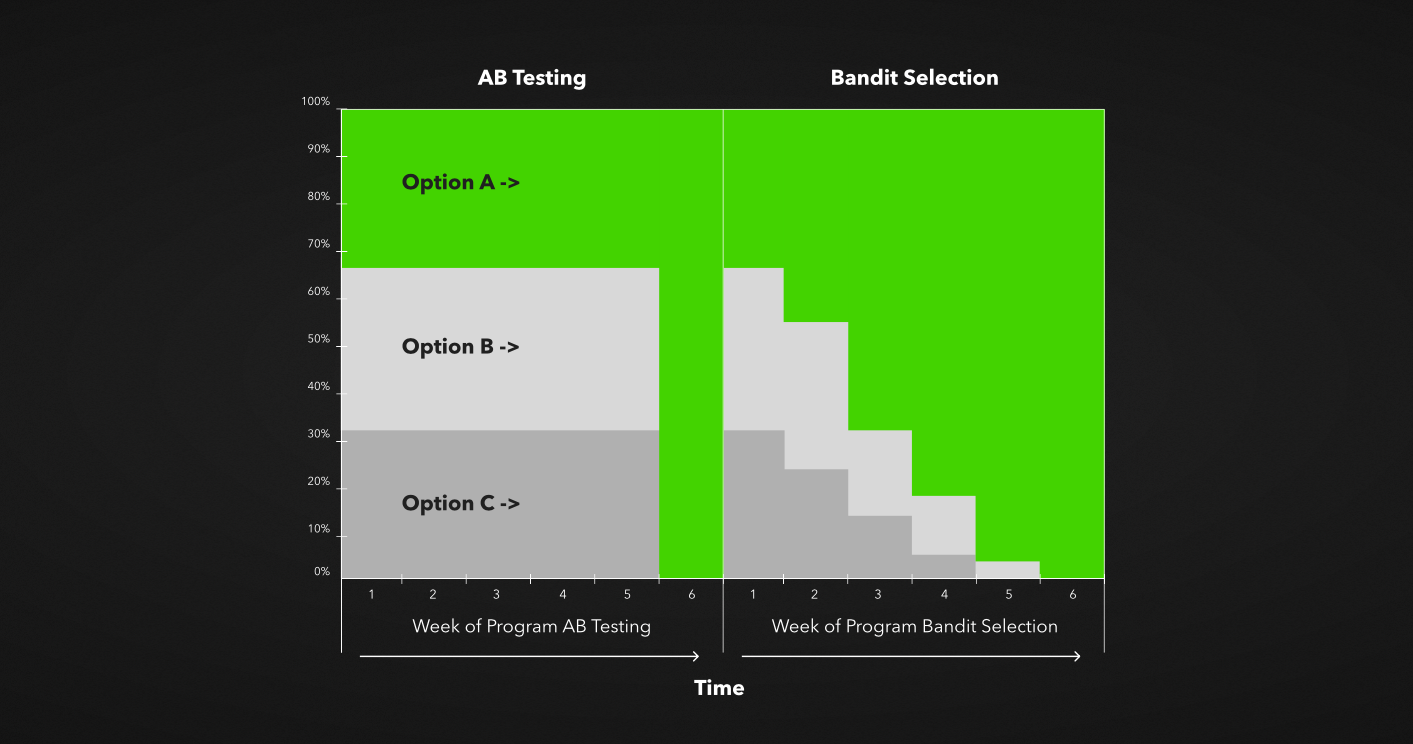
As we can see in the picture, if option A wins, the next day we increase the share of users who are given it. If on the third day we see that he wins again, then we increase his share. As a result, the winning group rolls out to 100%.
The Bayesian bandit adapts to time and change. It saves time to prescribe segments manually and analyze them. This helps to avoid the problem of peeping and saves on control. Above all: this is the automatic creation of new tests, which are expensive and difficult to implement in any product business.
Yes, tests are a lot of manual work. But if there is a mechanism that automatically detects good and bad options, then it will help for automatic tests.
How to understand that you are ready for A/B tests
Are you ready for A/B testing if you have:
- there is embedded analytics and tracking in the application;
- the economy is reduced (you understand how much one user will cost and you can scale it);
- there are resources for systematic hypothesis testing.
Conclusion: A/B tests can be carried out quickly, cheaply and easily if you know how to do it. And this should be done systematically. The point is not to run the test once and forget about it forever. You will get a qualitative effect only through chains of changes.