The authors of the Stable Diffusion neural network have announced the release of Stable Video Diffusion. This is a model that generates videos up to four seconds long based on an image or text description.
Stable Video Diffusion has two versions:
▫️SVD generates videos with a frequency of 14 frames per second;
▫️SVD-XT uses the same architecture as SVD, but increases the number of frames in generated videos to 24 per second.
According to Stability AI, the Stable Video Diffusion model shows itself better than the Runway GEN-2 and Pika Labs models in terms of generation quality.
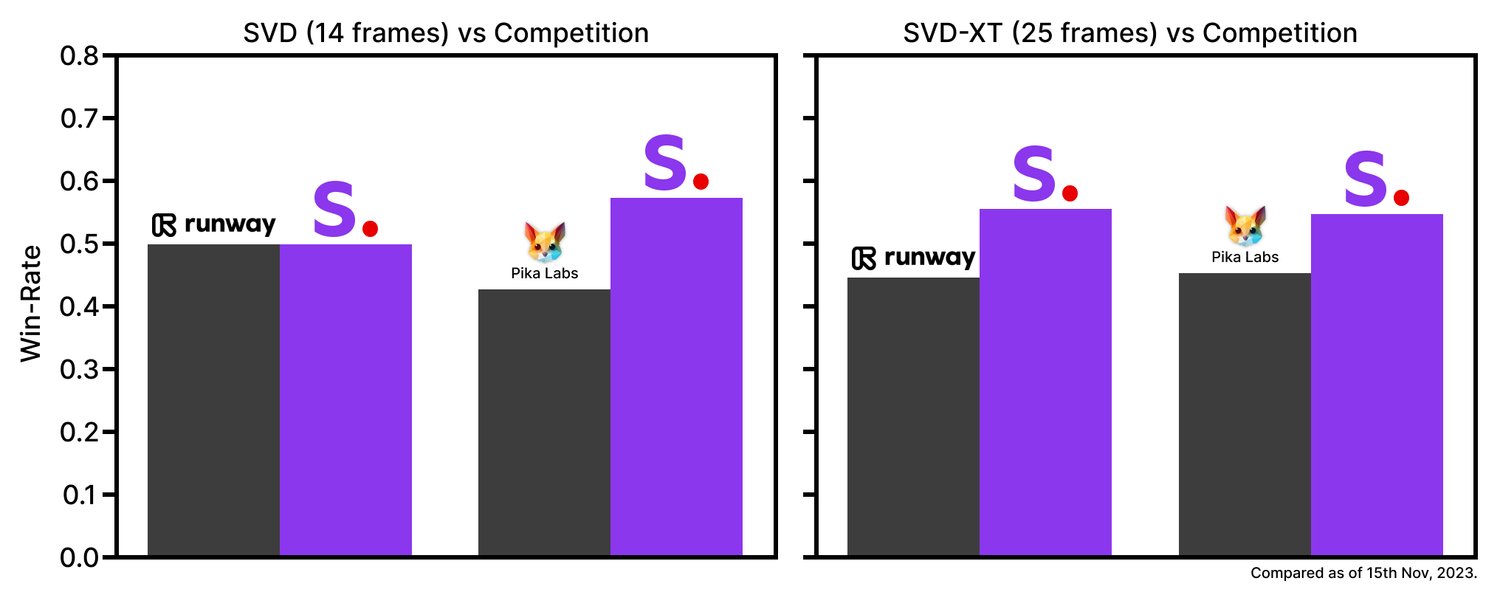
The company has placed the source code and weights of Stable Video Diffusion in the public domain. You can find them on GitHub and Hugging Face. Stability AI stressed that so far their model is intended only for research purposes.